Deteksi Objek dengan Python dan HuggingFace Transformers
YOLO! Jika Anda menyukai pembelajaran mesin, ini adalah istilah yang sudah tidak asing lagi. Memang, You Only Look Once telah menjadi salah satu pendekatan standar untuk deteksi objek dalam beberapa tahun terakhir. Didorong oleh kemajuan yang dibuat di ConvNets, banyak versi metode deteksi objek yang telah dibuat.
Namun, akhir-akhir ini, ada pesaing yang muncul - yaitu penggunaan model berbasis Transformer dalam visi komputer. Lebih khusus lagi, penggunaan Transformer untuk pendeteksian objek.
Dalam tutorial hari ini, Anda akan belajar tentang jenis model Transformer ini. Anda juga akan belajar membuat pipeline pendeteksian objek Anda sendiri dengan Python, model Transformer default dan pustaka HuggingFace Transformers. Bahkan, ini akan sangat mudah, jadi mari kita lihat!
Setelah membaca tutorial ini, Anda akan...
- Memahami untuk apa pendeteksian objek dapat digunakan.
- Mengetahui cara kerja model Transformer ketika digunakan untuk deteksi objek.
- Menerapkan pipeline berbasis model Transformer untuk deteksi objek (gambar) dengan Python dan HuggingFace Transformers.
Ayo kita mulai!
Apa yang dimaksud dengan deteksi objek?
Lihatlah sekeliling Anda. Kemungkinan, Anda akan melihat banyak hal - mungkin monitor komputer, keyboard dan mouse, atau ketika Anda menjelajah di browser ponsel, smartphone.
Ini semua adalah objek, contoh dari kelas tertentu. Pada gambar di bawah ini, misalnya, kita melihat contoh dari kelas manusia. Kita juga melihat banyak contoh dari class bottle. Sementara kelas adalah cetak biru, objek adalah yang sebenarnya, memiliki banyak karakteristik unik saat menjadi anggota kelas karena karakteristik yang dimiliki bersama.
Dalam gambar dan video, kita melihat banyak objek seperti itu. Ketika Anda membuat video lalu lintas, misalnya, kemungkinan besar Anda melihat banyak contoh pejalan kaki, mobil, sepeda, dan sebagainya. Dan mengetahui bahwa mereka ada dalam gambar bisa sangat bermanfaat!
Mengapa? Karena Anda bisa menghitungnya, untuk memberikan satu contoh. Hal ini memungkinkan Anda untuk mengatakan sesuatu tentang kepadatan suatu lingkungan. Contoh lainnya yaitu, mendeteksi tempat parkir di area yang ramai, sehingga Anda dapat memarkir mobil Anda.
Dan seterusnya.
Untuk itulah pendeteksian objek digunakan!

Pendeteksian objek dan Transformers
Secara tradisional, deteksi objek dilakukan dengan Jaringan Syaraf Tiruan. Biasanya, arsitektur mereka secara khusus disesuaikan untuk deteksi objek, karena mereka mengambil gambar sebagai input dan output kotak pembatas gambar.
Jika Anda terbiasa dengan jaringan saraf, Anda tahu bahwa ConvNets sangat berguna dalam mempelajari fitur-fitur penting dalam gambar, dan bahwa mereka tidak berubah secara spasial - dengan kata lain, tidak masalah di mana objek yang dipelajari berada dalam gambar atau berapa ukurannya. Jika jaringan mampu melihat karakteristik objek, dan mengasosiasikannya dengan kelas tertentu, maka jaringan dapat mengenalinya. Banyak kucing yang berbeda, misalnya, dapat dikenali sebagai contoh kelas kucing.
Namun, baru-baru ini, arsitektur Transformer telah mendapatkan perhatian yang signifikan di bidang pembelajaran mendalam - dan khususnya NLP. Transformer bekerja dengan mengkodekan input ke dalam keadaan dimensi tinggi, dan kemudian mendekodekannya kembali menjadi output yang diinginkan. Dengan menggunakan konsep perhatian diri secara cerdas, Transformers tidak hanya belajar untuk mendeteksi pola-pola tertentu, tetapi juga belajar untuk mengaitkan pola-pola tersebut dengan pola-pola lainnya. Dalam contoh kucing di atas, untuk memberikan satu contoh saja, Transformers dapat belajar mengasosiasikan kucing dengan tempat yang menjadi ciri khasnya - sofa, sebagai gambaran.
Jika Transformers dapat digunakan untuk klasifikasi gambar, maka tinggal selangkah lagi untuk menggunakannya untuk deteksi objek. Carion dkk. (2020) telah menunjukkan bahwa sebenarnya mungkin untuk menggunakan arsitektur berbasis Transformer untuk melakukannya. Dalam karya mereka End-to-End Object Detection with Transformers, mereka memperkenalkan Detection Transformer atau DeTr, yang akan kita gunakan untuk membuat pipeline deteksi objek hari ini.
Cara kerjanya adalah sebagai berikut, dan bahkan tidak meninggalkan CNN sepenuhnya:
- Dengan menggunakan Jaringan Syaraf Tiruan, fitur-fitur penting diambil dari gambar input. Fitur-fitur ini dikodekan secara posisional, seperti dalam bahasa Transformers, untuk membantu jaringan saraf mempelajari di mana fitur-fitur ini hadir dalam gambar.
- Input diratakan dan kemudian dikodekan ke dalam keadaan perantara, menggunakan encoder transformator, dan perhatian.
- Masukan ke dekoder transformator adalah keadaan ini dan serangkaian pertanyaan objek yang telah dipelajari, yang diperoleh selama proses pelatihan. Anda dapat membayangkannya sebagai pertanyaan, menanyakan "apakah ada objek di sini, karena saya pernah melihatnya sebelumnya dalam banyak kasus?", yang akan dijawab dengan menggunakan keadaan perantara.
- Memang, output decoder adalah serangkaian prediksi melalui beberapa kepala prediksi: satu untuk setiap pertanyaan. Karena jumlah kueri dalam DeTr diatur ke 100 secara default, DeTr hanya dapat memprediksi 100 objek dalam satu gambar, kecuali jika Anda mengonfigurasinya secara berbeda.

Bagaimana Transformers dapat digunakan untuk deteksi objek. Dari Carion dkk. (2020), Deteksi Objek End-to-End dengan Transformers, memperkenalkan DeTr Transformer yang digunakan dalam pipa ini.
HuggingFace Transformers dan Pipeline Deteksi Objeknya
Sekarang setelah Anda memahami cara kerja DeTr, sekarang saatnya menggunakannya untuk membuat pipeline pendeteksian objek yang sebenarnya!
Kita akan menggunakan HuggingFace Transformers untuk tujuan ini, yang dibuat untuk membuat bekerja dengan NLP dan Computer Vision Transformers menjadi mudah. Bahkan, sangat mudah sehingga menggunakannya bermuara pada pemuatan ObjectDetectionPipeline - yang secara default memuat DeTr Transformer yang dilatih dengan tulang punggung ResNet-50 untuk menghasilkan fitur gambar.
Mari kita mulai melihat detail teknologinya sekarang!
ObjectDetectionPipeline dapat dengan mudah diinisialisasi sebagai instance pipeline... dengan kata lain, dengan menggunakan pipeline("object-detection"), dan kita akan melihatnya pada contoh di bawah ini. Ketika Anda tidak memberikan masukan lain, ini adalah bagaimana pipeline diinisialisasi menurut GitHub (n.d.):
"object-detection": {
"impl": ObjectDetectionPipeline,
"tf": (),
"pt": (AutoModelForObjectDetection,) if is_torch_available() else (),
"default": {"model": {"pt": "facebook/detr-resnet-50"}},
"type": "image",
},
Tidak mengherankan jika sebuah instance ObjectDetectionPipeline digunakan, yang disesuaikan dengan deteksi objek. Dalam versi PyTorch dari HuggingFace Transformers, sebuah AutoModelForObjectDetection digunakan untuk tujuan ini.
Seperti yang telah Anda pelajari, secara default, model facebook/detr-resnet-50 digunakan untuk mendapatkan fitur gambar:
Model DEtection TRansformer (DETR) yang dilatih secara end-to-end pada deteksi objek COCO 2017 (118 gambar beranotasi). Model ini diperkenalkan dalam makalah End-to-End Object Detection with Transformers oleh Carrion et al.
HuggingFace (n.d.)
Dataset COCO (Common Objects in Context) adalah salah satu dataset standar yang digunakan untuk model pendeteksian objek dan digunakan untuk melatih model ini. Jangan khawatir, Anda juga dapat melatih model berbasis DeTr Anda sendiri!
Penting! Untuk menggunakan ObjectDetectionPipeline, paket timm - yang berisi model gambar PyTorch - harus sudah terinstal. Pastikan untuk menjalankan perintah ini jika Anda belum menginstalnya: pip install timm.
Menerapkan Pipeline Deteksi Objek yang Mudah dengan Python
Sekarang mari kita lihat bagaimana mengimplementasikan solusi yang mudah untuk Object Detection dengan Python.
Ingatlah bahwa kita menggunakan HuggingFace Transformers, yang harus diinstal pada sistem Anda - jalankan pip install transformers jika Anda belum memilikinya.
Kita juga mengasumsikan bahwa PyTorch, salah satu library terkemuka untuk deep learning saat ini, sudah terinstal. Ingatlah kembali ObjectDetectionPipeline yang akan dimuat di bawah tenda ketika memanggil pipeline("object-detection") tidak memiliki instance untuk TensorFlow, dan dengan demikian PyTorch diperlukan.
Ini adalah gambar yang akan kita gunakan untuk menjalankan pipeline deteksi objek yang kita buat, nanti di artikel ini:

Kami mulai dengan impor:
from transformers import pipeline
from PIL import Image, ImageDraw, ImageFont
Tentunya, kami menggunakan transformer, dan secara khusus representasi pipeline-nya. Kemudian, kita juga menggunakan PIL, sebuah pustaka Python untuk memuat, memvisualisasikan, dan memanipulasi gambar. Secara khusus, kami menggunakan impor pertama - Image untuk memuat gambar, ImageDraw untuk menggambar kotak pembatas dan label, yang terakhir ini juga membutuhkan ImageFont.
Berbicara tentang keduanya, selanjutnya adalah memuat font (kami memilih Arial) dan menginisialisasi pipeline pendeteksian objek yang telah kami perkenalkan di atas.
# Load font
font = ImageFont.truetype("arial.ttf", 40)
# Initialize the object detection pipeline
object_detector = pipeline("object-detection")
Kemudian, kita membuat sebuah fungsi bernama draw_bounding_box, yang - tidak mengherankan - akan digunakan untuk menggambar kotak pembatas. Fungsi ini mengambil gambar (im), probabilitas kelas, koordinat kotak pembatas, indeks kotak pembatas dalam daftar yang berisi kotak pembatas yang akan digunakan, dan panjang daftar tersebut sebagai masukan.
Di dalam fungsi tersebut, kita akan...
- Pertama, gambar kotak pembatas yang sebenarnya di atas gambar, yang direpresentasikan sebagai bbox rounded_rectangle dengan warna merah dan jari-jari kecil untuk memastikan tepiannya halus.
- Kedua, gambar label tekstual sedikit di atas kotak pembatas.
- Terakhir, kembalikan hasil antara, sehingga kita dapat menggambar kotak pembatas berikutnya dan label di atasnya.
# Draw bounding box definition
def draw_bounding_box(im, score, label, xmin, ymin, xmax, ymax, index, num_boxes):
""" Draw a bounding box. """
print(f"Drawing bounding box {index} of {num_boxes}...")
# Draw the actual bounding box
im_with_rectangle = ImageDraw.Draw(im)
im_with_rectangle.rounded_rectangle((xmin, ymin, xmax, ymax), outline = "red", width = 5, radius = 10)
# Draw the label
im_with_rectangle.text((xmin+35, ymin-25), label, fill="white", stroke_fill = "red", font = font)
# Return the intermediate result
return im
Yang tersisa adalah bagian intinya - menggunakan pipeline dan kemudian menggambar kotak pembatas berdasarkan hasilnya. Inilah cara kita melakukannya.
Pertama-tama, gambar - yang kita sebut street.jpg dan berada di direktori yang sama dengan skrip Python - akan dibuka dan disimpan dalam objek im PIL. Kita cukup mengumpankannya ke object_detector yang telah diinisialisasi - yang cukup untuk model untuk mengembalikan kotak pembatas! Perpustakaan Transformers akan menangani sisanya.
Kita kemudian menetapkan data ke beberapa variabel dan mengulang setiap hasil, menggambar kotak pembatas.
Terakhir, kita menyimpan gambar - ke street_bboxes.jpg.
Dan selesai!
# Open the image
with Image.open("street.jpg") as im:
# Perform object detection
bounding_boxes = object_detector(im)
# Iteration elements
num_boxes = len(bounding_boxes)
index = 0
# Draw bounding box for each result
for bounding_box in bounding_boxes:
# Get actual box
box = bounding_box["box"]
# Draw the bounding box
im = draw_bounding_box(im, bounding_box["score"], bounding_box["label"],\
box["xmin"], box["ymin"], box["xmax"], box["ymax"], index, num_boxes)
# Increase index by one
index += 1
# Save image
im.save("street_bboxes.jpg")
# Done
print("Done!")
Menggunakan model yang berbeda / menggunakan model Anda sendiri untuk deteksi objek
.... dan jika Anda membuat model sendiri, atau ingin menggunakan model yang berbeda, sangat mudah untuk menggunakan model tersebut sebagai pengganti DeTr Transformer berbasis ResNet-50.
Untuk melakukannya, Anda perlu menambahkan hal-hal berikut ini pada impor:
from transformers import DetrFeatureExtractor, DetrForObjectDetection
Kemudian, Anda dapat menginisialisasi ekstraktor fitur dan model, dan menginisialisasi object_detector dengan keduanya, bukan dengan default. Sebagai contoh, jika Anda ingin menggunakan ResNet-101 sebagai tulang punggung Anda, Anda dapat melakukan hal ini sebagai berikut:
# Initialize another model and feature extractor
feature_extractor = DetrFeatureExtractor.from_pretrained('facebook/detr-resnet-101')
model = DetrForObjectDetection.from_pretrained('facebook/detr-resnet-101')
# Initialize the object detection pipeline
object_detector = pipeline("object-detection", model = model, feature_extractor = feature_extractor)
Hasil
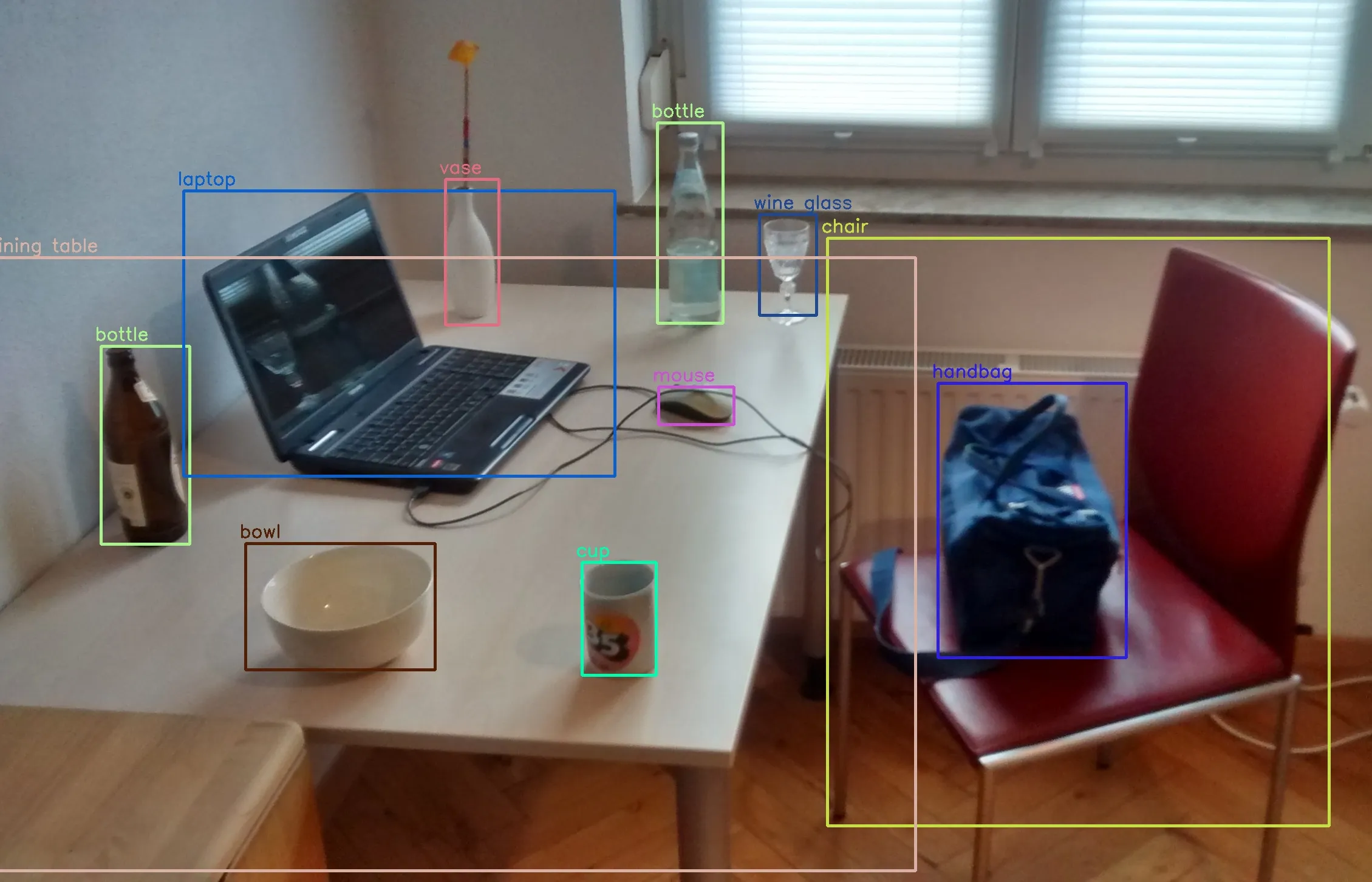
Inilah hasil yang kami dapatkan setelah menjalankan pipeline pendeteksian objek pada gambar input kami:

Atau, apabila diperbesar:

Contoh Pendeteksian Objek- kode lengkap
Kode lengkapnya dapat ditemukan di repositori pembelajaran mesin Github saya.
Selesai! Menggunakan Transformers untuk deteksi objek sangat mudah saat ini.
Setiap komentar, pertanyaan, atau saran akan diterima dengan senang hati. Terima kasih telah membaca artikel hari ini !!
Referensi
GitHub. (n.d.). Transformers/__init__.py di master - huggingface/transformers. https://github.com/huggingface/transformers/blob/master/src/transformers/pipelines/__init__.py
HuggingFace. (n.d.). Pipelines. Hugging Face - Komunitas AI yang membangun masa depan. https://huggingface.co/docs/transformers/v4.15.0/en/main_classes/pipelines#transformers.ObjectDetectionPipeline
HuggingFace. (n.d.). Facebook/detr-resnet-50 - Hugging face. Hugging Face - Komunitas AI yang membangun masa depan. https://huggingface.co/facebook/detr-resnet-50
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020, Agustus). Deteksi objek ujung-ke-ujung dengan transformer. In European Conference on Computer Vision (pp. 213-229). Springer, Cham.
Comments
Post a Comment